
4月29日凌晨,阿里巴巴开源新一代通义千问模型Qwen3(简称千问3),参数量仅为DeepSeek-R1的1/3,成本大幅下降,性能全面超越R1、OpenAI-o1等全球顶尖模型,登顶全球最强开源模型。
千问3是国内首个混合推理模型,性能更高的同时成本大幅下降,其总参数为235B,仅为R1的三分之一。有机构测算,部署R1需16张H20芯片,而满血版千问3仅需4张,成本大降75%。
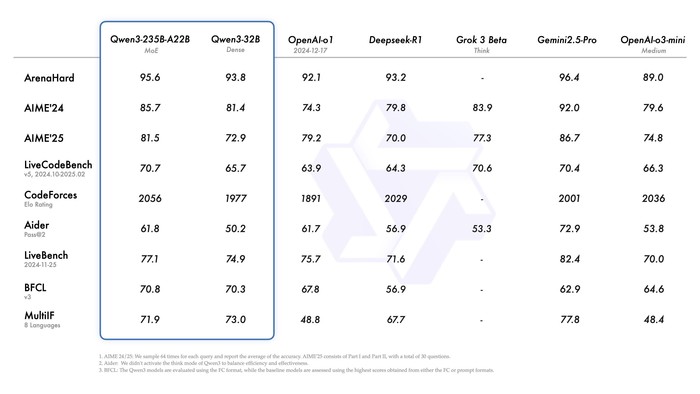
更重要的是,千问3为即将到来的智能体Agent和大模型应用爆发提供了更好的支持。在评估模型Agent能力的BFCL评测中,千问3创下70.8的新高,超越Gemini2.5-Pro、OpenAI-o1等顶尖模型。大幅降低Agent调用工具的门槛,或将引发新一轮AI应用爆发。
火星电波创始人、前MiniMax海螺AI产品负责人冯雷(橘子)在社交媒体上发布了他的测试体验。其中,Qwen3把各个MCP都调用成功了,但别的模型失败居多。他对界面新闻表示,从R1到千问3,工具调用能力已经进步了非常多。

Agent行业急需工具调用能力高的模型
Agent对模型能力的需求,取决于该 Agent 的任务复杂性和自治程度。
总体上,一个强健的Agent系统对底层模型的需求主要包括基础语言理解与生成、工具使用与调用、推理与规划等多方面的能力。简单来说,其需要准确理解指令和上下文以及多轮对话中的隐含意图和模糊表达,把复杂目标拆成子任务、按序执行。同时,这个系统还要理解和调用外部工具的流程,并执行API调用。
在Platform Thinking主理人、前知乎 COO张宁看来,目前Agent行业在底层模型上面临的痛点就是真正好工具调用能力的模型不多。
从千问3的性能和测试表现来看,阿里方面正在着力解决底层模型工具调用能力不足的痛点。可以在思考和非思考模式下精确集成外部工具,在复杂的基于代理的任务中在开源模型中表现领先。
在评估模型Agent能力的BFCL评测中,千问3创下70.8的新高,超越Gemini2.5-Pro、OpenAI-o1等顶尖模型,将大幅降低Agent调用工具的门槛。

千问3原生支持MCP协议,并具备强大的工具调用(function calling)能力,结合封装了工具调用模板和工具调用解析器的Qwen-Agent 框架,将大大降低编码复杂性,实现高效的手机及电脑Agent操作等任务。开发者要定义可用工具,可基于 MCP 配置文件,使用 Qwen-Agent 的集成工具或自行集成其他工具,快速开发一个带有设定、知识库RAG和工具使用能力的智能体。
同时,千问3在基础语言理解与生成能力和推理能力上也表现出不俗的能力。
这意味着,在同等模型能力的条件下,Agent以及AI应用行业调用模型的成本更低,调用更方便,这势必会促进更多新Agent以及AI应用的涌现。
坚定开源路线,多版本模型同时推出
千问3还提供了丰富的模型版本,包含2款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等6款密集模型
其中,千问3的30B参数MoE模型实现了10倍以上的模型性能杠杆提升,激活3B就能媲美上代Qwen2.5-32B模型性能;千问3的稠密模型性能继续突破, Qwen3-4B 这样的小模型也能达到 Qwen2.5-72B-Instruct 的性能。
因为所有千问3模型都是混合推理模型,API可按需设置“思考预算”(即预期最大深度思考的tokens数量),进行不同程度的思考,灵活满足AI应用和不同场景对性能和成本的多样需求。中小企业和AI开发者可根据自己需求灵活选择模型,这势必会降低其使用大模型的门槛和成本。这些资金和人员都非常有限的团队可以把更多资源和精力投入到市场和用户需求痛点的挖掘上,以便能研发出更多创新应用。
在冯雷看来,Qwen 系列模型,因为开源、小巧、好微调的特点,已经成为很多开发者的首选模型。很多强化学习研究也都依赖Qwen 系列的高质量基座,因为基座模型的质量决定了后续强化学习的上限。

阿里云走到第16个年头,全面重构了一个从底层硬件到计算、存储、网络、数据处理、模型训练和推理平台的全栈技术架构体系,是亚太第一的云计算平台;而阿里也是全球最早投入大模型研究的科技公司之一
此前周靖人接受媒体采访时称,大模型发展和云体系的支撑不可分割。无论训练还是推理,大模型的每一次突破,表面看是模型能力演进,背后其实是整个云计算和数据、工程平台的全面配合和升级。多模态也是通向 AGI 的重要途径。
阿里Qwen 3发布后,马斯克在社交平台X上称,下周,Grok 3.5 早期测试版将仅向SuperGrok订阅者发布。它是第一个能够准确回答有关火箭发动机或电化学技术问题的人工智能。这也意味着Qwen 3在国际上同样有较高的关注度。
清华大学人工智能研究院常务副院长、欧洲人文和自然科学院外籍院士孙茂松表示,近年来在人工智能领域尤其是大模型的发展上,发出了很强烈的中国的声音,DeepSeek的出现以及通义千问的系列开源产品极大推动了国内大模型的开源路线,这无疑为缓解技术垄断,推动技术平权,提升人工智能的普惠性,无疑具有十分重要的作用。
目前,海内外开源社区中Qwen的衍生模型数量已突破10万,超越Llama系列衍生模型,通义千问Qwen稳居世界最大的生成式语言模型族群。根据Huggingface2025年2月10日最新的全球开源大模型榜单,排名前十的开源大模型全部是基于通义千问Qwen开源模型二次开发的衍生模型。
孙茂松认为,这意味着中国的大模型的文化在国际上得到了认可,这是在文化层面有某种扭转,外界看来似乎“漫不经心”,但这一点非常难能可贵,这实际上是认可中国大模型的发展和技术。





































溪夕汐笔趣阁")













 47847
47847 26
26


 47847
47847 26
26


 48158
48158 46
46


 18095
18095 59
59


 76276
76276 17
17


 65573
65573 36
36


 63128
63128 4
4


 86478
86478 85
85


 30367
30367 78
78


 63524
63524 2
2


 62738
62738 4
4


 31856
31856 47
47


 71272
71272 50
50


 83067
83067 20
20


 99712
99712 97
97


 54978
54978 31
31


 63720
63720 90
90


 94331
94331 53
53


 29063
29063 54
54


 68942
68942 21
21


 89181
89181 94
94


 23218
23218 58
58


 28745
28745 52
52


 81201
81201 44
44


 17391
17391 69
69

 29549
29549 6
6


 17480
17480 70
70


 89028
89028 4
4


 98746
98746 88
88


 79267
79267 68
68


 83517
83517 81
81


 27017
27017 78
78


 54410
54410 77
77


 62398
62398 1
1


 63428
63428 58
58


 63473
63473 31
31


 47199
47199 19
19


 84052
84052 15
15


 46245
46245


 19684
19684 80
80


 22271
22271 49
49


 94874
94874 50
50


 36152
36152 35
35


 45060
45060 29
29


 74946
74946 99
99


 90160
90160 42
42

 41857
41857 2
2


 66369
66369 8
8


 47534
47534 52
52


 61701
61701 41
41


 52980
52980 33
33


 50061
50061 60
60


 68054
68054 69
69


 93840
93840 53
53


 92885
92885 11
11